[데이터 아키텍처] DA 구축 예제 | 4. 현행 논리 데이터 모델링
< 목차 >
2. 현행 DB 준비 - 파일 업로드 (feat. 파이썬)
4. 현행 논리 데이터 모델링
현행 논리 데이터 모델링을 시작하기 전에 중요한 것은 대상 테이블을 확정하는 것이다. 즉, 현행 테이블의 모수를 확정하는 것이다
.
모수가 확정이 되었다면, 현행 논리 데이터 모델링은 현재의 ASIS 모습을 나타내는데 중점을 두고 작업을 진행한다. 즉, 데이터 모델의 현행화 및 상세화 작업이다.
본 [DA 구축 예제] 연재에서 모수는 12개의 테이블이고 이전 포스트(리버스 모델링)에서 리버스를 수행하여 데이터 모델을 생성하였으므로 리버스 데이터 모델로부터 현행 논리 데이터 모델링을 진행한다.
이전 포스트(리버스 모델링)에서의 전제조건이 DB 오브젝트와 엑셀 테이블/컬럼 목록이 일치한다는 전제 조건이므로 현행화 작업은 불필요하다.
따라서, 본 포스트에서는 상세화 작업 중 해당 리버스 모델에 필요한 상세화 작업을 진행한다.
먼저, 리버스 모델은 아래와 같다.

1) 데이터 모델 재배치
연관성이 있는 엔터티를 상호 근처에 배치한다. 추후 직접적인 관계가 있는 엔터티 간에 관계를 설정하기 위함이다.

2) 식별자 지정
일반적으로 식별자가 정의되지 않는 경우는 흔하지 않으나 본 리버스 모델은 모든 엔터티에 식별자가 없으므로 식별자를 부여한다.
식별자를 부여하는 방법은 직관적으로 알 수 있는 경우도 있고 데이터 분석을 통해 유일성을 조사하여 확인해야 하는 경우도 있다.
본 예제에서는 A_병원정보서비스 및 B_약국정보서비스 엔터티는 암호화요양기호가 식별자임을 직관적으로 알 수 있으므로 데이터 모델에 식별자(#) 표시를 한다.
만약, 데이터 분석을 통해 유일성을 확인해야 한다면 해당 SQL을 실행하여 확인한다.
예를 들어, A_병원정보서비스 엔터티의 유일성 체크는 아래와 같다.
SELECT 암호화요양기호, COUNT(*)
FROM A_병원정보서비스
GROUP BY 암호화요양기호
HAVING COUNT(*) > 1
또 다른 예제는 기타인력정보 엔터티이다.
SELECT 암호화요양기호, COUNT(*)
FROM C10_기타인력정보
GROUP BY 암호화요양기호
HAVING COUNT(*) > 1
C10_기타인력정보 엔터티의 유일성 체크 결과는 아래와 같다. 즉, 암호화요양기호 속성으로는 유일성을 보장 못하는 것이다.

해당 SQL에 기타인력코드를 추가한다.
SELECT 암호화요양기호, 기타인력코드, COUNT(*)
FROM C10_기타인력정보
GROUP BY 암호화요양기호, 기타인력코드
HAVING COUNT(*) > 1
해당 SQL의 결과가 없으므로 기타인력코드 까지가 유일성을 보장한다. 즉, C10_기타인력정보 엔터티의 식별자는 「암호화요양기호+기타인력코드」 이다.
나머지 엔터티에 대해서도 위와 같은 방법으로 SQL을 활용하여 유일성 조사를 통해 식별자를 조사하고 부여한다.
마지막으로, C04_교통정보 엔터티의 유일성 조사 과정을 보자. 앞에서 진행한 것처럼 컬럼을 추가해 가면서 유일성을 조사한다.
SELECT 암호화요양기호, 교통편명, COUNT(*)
FROM C04_교통정보
GROUP BY 암호화요양기호, 교통편명
HAVING COUNT(*) > 1
컬럼을 하나씩 추가해 가면서 결과가 없을 때까지 유일성을 체크한다.
SELECT 암호화요양기호, 교통편명, 노선번호, 하차지점, 방향, 거리, 비고, COUNT(*)
FROM C04_교통정보
GROUP BY 암호화요양기호, 교통편명, 노선번호, 하차지점, 방향, 거리, 비고
HAVING COUNT(*) > 1
마지막으로, 하나씩 컬럼을 추가해 가면서 모든 컬럼을 가지고 유일성 조사를 하였는데도 불구하고 중복 건이 발생하였다. 즉, 모든 컬럼을 식별자로 정의해도 유일성을 보장하지 못한다는 것이다. 즉, 식별자 정의가 불가능하다.
따라서, 추후 목표 논리 데이터 모델링 시 C04_교통정보 엔터티의 식별자를 추가로 부여하고 또한 데이터 이행 시 중복 데이터에 대한 처리 방안도 고민해야 한다.
3) 관계 설정
병원정보서비스 및 약국정보서비스 엔터티가 부모가 되고 나머지 엔터티들은 자식으로서 관계를 형성한다는 것을 직관적으로 알 수 있다.
그런데 여기서 확실하지 않은 것은 부모가 병원정보서비스 엔터티 인지 아니면 병원정보서비스 및 약국정보서비스 엔터티가 배타적으로 부모인지를 알 수가 없다.
따라서, 데이터 분석을 통해 관계를 조사하여 관계를 설정해야 한다. 관계를 조사하는 과정은 다음과 같다.
예를 들어, C01_시설정보 엔터티에 대한 관계 조사 내용은 아래와 같다.
SELECT '병원' 구분, COUNT(*)
FROM A_병원정보서비스 A
INNER JOIN C01_시설정보 B
ON A.암호화요양기호 = B.암호화요양기호
UNION ALL
SELECT '약국', COUNT(*)
FROM B_약국정보서비스 A
INNER JOIN C01_시설정보 B
ON A.암호화요양기호 = B.암호화요양기호

의료기관시설정보 엔터티는 병원정보서비스 및 약국정보서비스 엔터티의 자식으로서 시설의 상세 정보를 관리하는 엔터티이다.
데이터 분석한 결과를 근거로 관계 설정을 하면 아래와 같다.

즉, 의료기관시설정보 엔터티의 부모는 병원정보서비스와 약국정보서비스 엔터티이고 배타 관계를 가진다.
두 번째, C03_진료과목정보 엔터티에 대한 관계 조사 내용은 아래와 같다.
SELECT '병원' 구분, COUNT(*)
FROM A_병원정보서비스 A
INNER JOIN C03_진료과목정보 B
ON A.암호화요양기호 = B.암호화요양기호
UNION ALL
SELECT '약국', COUNT(*)
FROM B_약국정보서비스 A
INNER JOIN C03_진료과목정보 B
ON A.암호화요양기호 = B.암호화요양기호
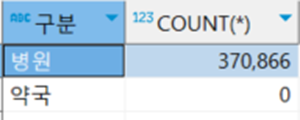
데이터 분석한 결과를 근거로 관계 설정을 하면 아래와 같다.

즉, 의료기관진료과목정보 엔터티의 부모는 병원정보서비스 엔터티이다.
이와 같은 방법을 통해 나머지 엔터티의 관계를 조사하여 현행 논리 데이터 모델링을 진행하였다.
상세화 작업을 수행하여 작성된 현행 논리 데이터 모델은 아래와 같다.

'데이터 아키텍처' 카테고리의 다른 글
| [데이터 아키텍처] DA 구축 예제 | 6. 현행 모델 문제점 분석 (0) | 2024.05.22 |
|---|---|
| [데이터 아키텍처] DA 구축 예제 | 5. 현행 개념 데이터 모델링 (0) | 2024.05.21 |
| [데이터 아키텍처] DA 구축 예제 | 3. 리버스 모델링 (0) | 2024.05.16 |
| [데이터 아키텍처] DA 구축 예제 | 2. 현행 DB 준비 (feat. 파이썬) (0) | 2024.05.15 |
| [데이터 아키텍처] DA 구축 절차 (0) | 2024.05.15 |



